AWSコストをpandasで分析するためのツールを作った
最近 cepan というAWSコスト分析用のPythonライブラリを作りました。
これは何?
JupyterのようなNotebook上でAWSコストを分析するためのツールです。
boto3のCostExplorer APIをラップしたライブラリでデータをpandas.Dataframe形式でデータを返してくれます。
boto3のAPIと”ほぼ”同じインタフェースで使うことができます。 例えば2021年2月と3月の月次コストをS3のコストに絞ってUSAGE_TYPE別に取得したい場合は以下のようなコードを書きます。
from datetime import datetime import cepan as ce df = ce.get_cost_and_usage( time_period=ce.TimePeriod( start=datetime(2021, 2, 1), end=datetime(2021, 4, 1) ), granularity="MONTHLY", group_by=ce.GroupBy( dimensions=["USAGE_TYPE"] ), filter=ce.Dimensions(key="SERVICE",values=["S3"]) )
こんな感じでデータが帰ってきます (私の個人AWSアカウントの数値なので額はしょぼい)
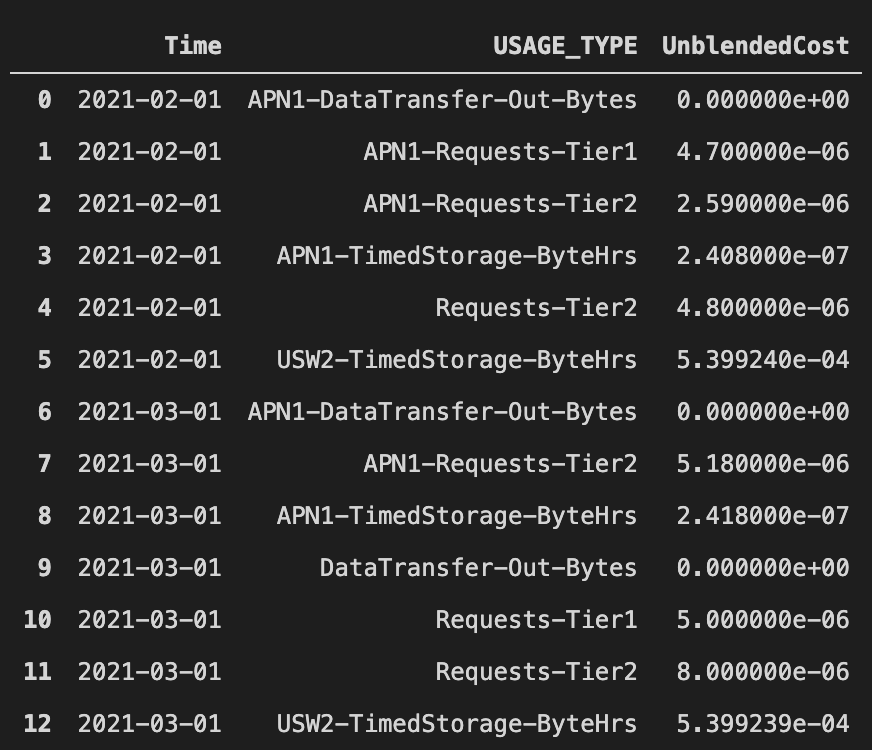
Dataframeでデータを返すので加工はよしなに行うことができ、例えば上述のデータを加工して前月とのコスト比を出す、とかできます。
df = df.pivot(index=['USAGE_TYPE'], columns='Time', values='UnblendedCost').fillna(0) df['Diff'] = df["2021-03-01"] - df["2021-02-01"]

cepanではなるべくboto3の引数名やデータ構造を合わせつつも、ネストしたDictを要求するような複雑な引数に対してはデータ型を定義するようにしています。 そのため補完による入力補助をうけることができます。
その他の便利機能として、例えばCostExplorer APIだとS3のコストだけを取得するためにはフィルターに Amazon Simple Storage Service と入力しないといけないのですが、長くて大変面倒なので、S3 と入力しても大丈夫なようにしています。その手のサービス名のエイリアスを幾つか定義しており、全量はここで見れます。
こんな感じで使っているよ
ギョームでAWSコストの分析を定期的に行って、コスト感と改善ポイントの把握する必要があり、その分析業務をcepanとJuputerで行っています。 素のboto3だと入力も戻り値も複雑にネストしたDictなので使いにくいですが、cepanだとシュッとDataframeでデータを取得できるのですぐに分析に移ることができます。
サービス別の前月コスト比や、各主要サービスの日別、USAGE_TYPE別のコストグラフなどを出すノートブックを作って定形の分析作業を半自動化しつつ、気になるデータがあったら追加で詳しく見ていくみたいな運用をしています。 またDataframeの加工のしやすさを活かして、リクエスト数のデータとAWSコストのデータをかけ合わせてリクエスト数に対するコストの推移は妥当であるか?みたいなことも見ていたりします。(アドテクはコスパが大事なので)
手軽さではコンソールのAWS CostExplorerには劣るのですが、ちょっと計算を加えたり、定形作業として複数の可視化と分析を半自動化したいみたいなケースでは便利だと思うので使ってみてください。
golangで末尾の改行を削除する際はstrings.TrimSpace使う
無駄にハマって時間を費やしたので備忘。
とあるCSVをパースするバッチをgolangで書いていて以下のようなコードを書いていた。
csv := strings.TrimRight(record, "\n") columns := strings.Split(csv, ",")
でも上記のコードだと何故かcolumnsの最後の要素に改行がついてて、あれれ〜?おかしいな〜??ってなってたら、インプットのCSVの改行コードが"\r"でござった。
じゃあ、改行コードの種類を気にせずどうやってトリムすれば良いかというとstrings.TrimSpaceを使えって話。
csv := strings.TrimSpace(record)
columns := strings.Split(csv, ",")
これなら改行コードの種類に限らず全部消してくれる。空白も消える。ついでに末尾だけでなく先頭もからも消えるけどほとんど場合は問題ない。
最初はTrimSpaceは空白だけ消してくれると思い込んでたんだけど、そんなことはなくUnicodeで空白とみなしている'\t', '\n', '\v', '\f', '\r', ' ', U+0085 (NEL), U+00A0 (NBSP)を消すらしい。
GoDocちゃんと見ろという話であった。
golangで設定ファイルを環境変数に対応させる
背景
対応
ここに全て書いてあった。
go: Using environment variables in configuration files - M. Tarık Yurt
ioutilでReadFileした後に、string型にしてos.ExpandEnvを一回噛ませて、Unmarshalすればよいだけ。超簡単。 つまりこんな感じ。
func LoadFile(filename string, v interface{}) error { content, err := ioutil.ReadFile(filename) if err != nil { return err } expandContent := []byte(os.ExpandEnv(string(content))) err = yaml.UnmarshalStrict(expandContent, v) if err != nil { return fmt.Errorf("parsing YAML file %s: %v", filename, err) } return nil }
先人の知恵に感謝。
Hiveによるデータの洗い替え処理の検証
目的
Hiveによってデータを洗い替えする際の処理パターンを検討する
はじめに
Hive、というよりHDFSにおいてデータはimmutableな物として扱ったほうが良い。 パフォーマンスの観点から追記や更新を表現するような処理パターンは避けた方が無難である。 なぜならHDFSはHDD上に大量のデータをシーケンシャルに一気に書き込む事でパフォーマンスを稼ぐ事を前提に設計されているためである。 追記のような処理あるいは部分更新を実現するために過剰なパーティション構造にすると、細分化されたファイルが大量にできる。 細分化されたファイルはランダムリードの増加やNameNodeの負荷増加に繋がる。 更新や追記をヘビーに使いたい用途においてはHBaseやKuduを使った方が良い。 しかし、処理によってはどうしてもHDFS上のデータを更新したいケースが出てくる。
そういたケースでは、対象のデータあるいはパーティションをまるっと作り直した方が、参照のパフォーマンスは良くなる。 もちろん対象のデータセットのサイズにもよるが、十分大きいクラスタであれば大概のデータは作り直せる。
洗い替え処理
前提として対象データはExternalテーブルとする。 まず対象データのDDLにおいて通常の処理で利用するパーティション階層に加えてversionというパーティションを加える。
CREATE EXTERNAL TABLE access_log ( remote_host STRING, ident STRING, user STRING, time STRING, raw_request STRING, respons_code INT, byte INT, referrer STRING, user_agent STRING, response_time_microsecond INT, host STRING ) PARTITIONED BY(dt STRING, version STRING) STORED AS ORC LOCATION '/data/kanga333/access_log/';
そして適当なクエリでデータを挿入する。(以下のクエリは一例。わかりやすさのためdtを明示的な値として渡している)
FROM access_log_origin INSERT OVERWRITE TABLE access_log partition(dt, version) SELECT *, '20180101', '1';
作成したテーブルはHDFSから見ると以下のようなディレクトリ構造となる。
/data/kanga333/access_log/dt=20180105/version=1
この状態において以下のクエリを実行し、HDFS上にエイリアスのパーティション’latest’を作成する。
ALTER TABLE access_log ADD PARTITION (dt = '20180101', version = 'latest') location '/data/kanga333/access_log/dt=20180101/version=1'
基本的に該当テーブルに対する参照クエリはversionパーティションをlatestに指定してクエリを実行する。
SELECT count(*) FROM access_log WHERE dt = '20180101' AND version = 'latest'
データを作り直したくなった場合はversionパーティションをインクリメントして新しいパーティションを作成する。
FROM access_log_origin INSERT OVERWRITE TABLE access_log partition(dt, version) SELECT *, '20180101', '2';
その後、latestパーティションの向き先をalterにより変更する。
ALTER TABLE access_log PARTITION (dt = '20180101', version = 'latest') SET LOCATION '/data/kanga333/access_log/dt=20180101/version=2'
これにより参照を止めることなく、データの作り直しが可能になる。
2017年の振り返り
年の瀬なので2017年を振り返ってみる。
2017年の抱負
2017年は以下のような抱負を掲げていた。
今年は草を生やして行きたいです。
— かんが (@kanga333) 2016年12月31日
実際はどうだったかというと

微妙な結果だ。
反省
今年は2度のタイミングで"Write Code Every Day"を実行しようと試みた。しかし、どちらも途中で挫折してしまっている。その形跡が1月~2月と4月~7月あたりに見て取れる。 毎日コードをコミットするのはそれなりに大変だ。時として突発的な飲み会に参加してコードを書く時間が用意できない場合など出てくる。そんな時はREADMEをちょっと弄ったり、中途半端な修正状況でコミットするという小手先のコミットをしてしまう。そのようなコミット続けると”意味の無いことをやっているのでは”とか”毎日のコミットに固執せず、ちゃんと意味のある本質的なコミットをしたほうが良いのでは"という考えが頭をよぎってしまう。そうして草を一日落とす。すると草を落とす事に抵抗が無くなってしまう。そしていつの間にかコードを書く習慣から遠ざかってしまう。
それらを踏まえて来年に向けた対策を挙げる。
- 何より毎日草を生やし続けるという制約自体を重視する
- 朝に草を生やす
- 草を生やしやすいようにプロダクトを色々持つ
来年こそは"Write Code Every Day"を続けていきたいと思っている。しかし6月に新婚旅行を予定しているため、そこで草は一度途絶えてしまうだろう。そのことが自分のモチベーションにどう影響するかは不明だ。
対外的なアウトプットについて
今年は以下のアウトプットを行った。
去年がほぼ0であったことを考えるとすこしづつマシなエンジニアに近づきつつあるような気がする。しかし自分の年齢を鑑みると、まだまだアウトプットの量が足りないので来年は倍以上にしていきたい。
仕事について
技術検証や導入を主にやっていた。会社にはそれなりに評価して貰っていると思う。しかし、検証してるだけでは会社のシステムへ貢献にはならないので、しっかり導入をやり切って良いシステムを作っていきたい。そして来年はインフラまわりの仕事は抑えて、コードを書く割合を半分くらいまで増やしたい。
他には最近、採用活動に携わる事が増えてきた。対外的な求人力を高める事は、自分の働く環境を良くする事につながるのでそちらも力を入れていきたい。
副業について
10月頃から副業を始めた。前職の同期が企業したのでそのよしみでインフラ周りを手伝っている。 会社で使っている技術と違う技術が使えるためそれなりに面白い。しかし、学習時間が中々取れなくなってしまうので副業タスクをどう効率化していくかというのが来年の課題だ。
資産運用について
資産運用を始めた。そろそろお金でお金を生むスキルを身に着けないと人生厳しそうだなと感じる。今年はとりあえずNIISAを始めて、401kを真面目に設定し直した。来年は勉強して一部の資産でもう少しアグレッシブな運用をしてみようと思う。
まとめ
つらつらと今年を振り返った。振り返って感じたことだが、今年は色々と始めてみた年だったようだ。来年は始めてみたことを良いサイクルに乗せれるようにしていきたい。
PostgreSQLをレプリ構成で立てるまでの記録
あらすじ
こんな便利な時代に自前でPostgreSQLを立てる必要が出た。悲しきオンプレのさだめよ。 当方PostgreSQL素人なのでいちから構築手順をメモしていく。
要件
ミドルウェアが利用するPostgreSQLでそんなにパフォーマンスも容量もいらない。 でも、ちゃんと冗長化していて欲しいし、障害時にはフェイルオーバして欲しい。そんな感じ。
全体像
とりあえずPostgreSQLの同期レプリケーションでアクティブ/スタンバイの構成を作りたい。
使用バージョン
- OS:CentOS7
- PostgreSQL:9.6の最新
インストール手順
yumレポジトリをインストールするrpmパッケージの入手
ここにある。
PostgreSQL RPM Repository (with Yum)
以下のコマンドにてpostgresqlのレポジトリがyum.repoに追加される。
yum install -y https://download.postgresql.org/pub/repos/yum/9.6/redhat/rhel-7-x86_64/pgdg-centos96-9.6-3.noarch.rpm
postgresql-serverのインストール
そして実際のpostgresqlサーバのインストール。
yum install -y postgresql96-server
データベースディレクトリの初期化
サービスを起動するまえにデータベースディレクトリが必要なそうな。データベースあるある。
/usr/pgsql-9.6/bin/postgresql96-setup initdb
/var/lib/pgsql/9.6/data/を覗くと色々ファイルができていた。
サービス起動
初期化後にサービスを立ち上げるとpostgresqlが立ちあがる。
# systemctl start postgresql-9.6
# systemctl status postgresql-9.6
● postgresql-9.6.service - PostgreSQL 9.6 database server
Loaded: loaded (/usr/lib/systemd/system/postgresql-9.6.service; disabled; vendor preset: disabled)
Active: active (running) since 水 2017-10-04 04:40:31 UTC; 5s ago
Process: 28155 ExecStartPre=/usr/pgsql-9.6/bin/postgresql96-check-db-dir ${PGDATA} (code=exited, status=0/SUCCESS)
Main PID: 28161 (postmaster)
CGroup: /system.slice/postgresql-9.6.service
├─28161 /usr/pgsql-9.6/bin/postmaster -D /var/lib/pgsql/9.6/data/
├─28163 postgres: logger process
├─28165 postgres: checkpointer process
├─28166 postgres: writer process
├─28167 postgres: wal writer process
├─28168 postgres: autovacuum launcher process
└─28169 postgres: stats collector process
10月 04 04:40:31 test-pg-1 systemd[1]: Starting PostgreSQL 9.6 database server...
10月 04 04:40:31 test-pg-1 postmaster[28161]: < 2017-10-04 04:40:31.246 UTC > LOG: redirecting log output to logging collector process
10月 04 04:40:31 test-pg-1 postmaster[28161]: < 2017-10-04 04:40:31.246 UTC > HINT: Future log output will appear in directory "pg_log".
10月 04 04:40:31 test-pg-1 systemd[1]: Started PostgreSQL 9.6 database server.
おKおK
各種設定
一旦、Postgresqlサーバを止めて各種設定を確定させて行く。前述したとおりパフォーマンス要件は厳しく無いので、セキュリティやloggingの設定を主に注意してやっていく。
が、ここで問題が発生して、どうもpostgresqlの設定ファイルはinitdbで作成するディレクトリの/var/lib/pgsql/9.6/data/の下にできるそうな。
個人的には設定ファイルは/etc/pgsqlの下におかれていて欲しいなぁ。。。と思っていたと所、以下のドキュメントを発見した。
PostgreSQL: Documentation: 9.6: File Locations
これを読む限り、config_fileパラメータを起動時に渡してやれば諸々上手くいくそうだ。systemdのユニットファイルをいじれば良さそう。
以下は個々のconfigファイルについて
接続周り
listen_addresses = '*'
全部のIPで待ち受けますよ的なおなじみのやつ。
WAL/レプリケーション
wal_level = replica max_wal_senders = 5 max_replication_slots = 2 track_commit_timestamp = on
wal_lebel
max_wal_senders
- walをレプリスレーブに送信するプロセス数
- 再接続に備えて、実際のスレーブ数より少し多めにすると良いらしい
max_replication_slots
- レプリスレーブがどこまでwalを読んだか?という情報を管理するためのスロット数
- レプリ台数にする必要がある
- また、一度上げてから下げようとするとエラーになるらしい
- 同期レプリの場合いらない気もするけども、とりあえず設定
マスタ固有
synchronous_standby_names = '1 (pg2, pg3)'
同期レプリするための設定なので、レプリ先がいない状態で反映すると動かなくなる
スレーブ固有
hot_standby = on
スタンバイ側でクエリを許可
ロギング設定
log_destination = 'stderr' logging_collector = on log_directory = '/var/log/pg_log' log_filename = 'postgresql-%a.log' log_truncate_on_rotation = on log_rotation_age = 1d log_line_prefix = '< %m > ' log_timezone = 'UTC'
ほとんどデフォルトでコメントアウトされていなかったパラメータそのまま。 log_directoryだけ、/var/log下に書き込まれるとうにへんこうした、、、がlog_destinationが'stderr'なので本当に吐かれるかは疑問。 log_destinationをstderrのままにしているのはsystemdのjournaldにログを監視してもらうため。
クライアント接続設定
datestyle = 'iso, mdy' timezone = 'UTC' lc_messages = 'en_US.UTF-8' lc_monetary = 'en_US.UTF-8' lc_numeric = 'en_US.UTF-8' lc_time = 'en_US.UTF-8' default_text_search_config = 'pg_catalog.english'
デフォルトでコメントアウトされていなかったパラメータそのまま。
パフォーマンス設定
何度も言うが、パフォーマンス要件は厳しく無い。 基本的なパフォーマンスの設定だけ抑えておけると良いのだが、何か良い記事は無いかとあさってるといかのページにたどり着いた。
なにやらHW状態に合わせて設定を生成してくれるらしい。これを使って実運用で問題出たら都度チューニングしていこう。 検証環境に合わせて生成すると以下の感じになった。
max_connections = 1024 shared_buffers = 1GB effective_cache_size = 3GB work_mem = 1MB maintenance_work_mem = 256MB min_wal_size = 1GB max_wal_size = 2GB checkpoint_completion_target = 0.7 wal_buffers = 16MB default_statistics_target = 100
ディレクトリとパス設定
include_dir = 'conf.d'
コンフィグファイルは分割してincludeできるみたいなので、よしなにincludeさせる。
認証ファイル設定
ホスト認証周りの設定はpg_hba.confで行うようだ。
とりあえず、社内DCにいるサーバにはhogeユーザでhogeデータベースにパスワード指定でログイン可能なようにゆるく許可を与える。
あと検証なので、レプリもゆるく開けている。
# TYPE DATABASE USER ADDRESS METHOD local all all peer host sameuser hoge 192.168.0.0/16 md5 host replication postgres 192.168.0.0/16 trust
一瞬、このファイルを設定変更した際、リスタートせんとアカンのん??と思ったが、SIGHUPでリロードしてくれるらしい。ですよねー。良かった。
systemdの設定
個別の設定ファイルをロードさせるためにsystemdのUnitファイルを変更する。
[Unit]
Description=PostgreSQL 9.6 database server
After=syslog.target
After=network.target
[Service]
Type=notify
User=postgres
Group=postgres
PermissionsStartOnly=true
Environment=PGDATA=/var/lib/pgsql/9.6/data/
Environment=PGCONFIG=/etc/pgsql/
OOMScoreAdjust=-1000
ExecStartPre=-/usr/pgsql-9.6/bin/postgresql96-setup initdb
ExecStartPre=/usr/pgsql-9.6/bin/postgresql96-check-db-dir ${PGDATA}
ExecStart=/usr/pgsql-9.6/bin/postmaster \
-c config_file=${PGCONFIG}/postgresql.conf \
-c hba_file=${PGCONFIG}/pg_hba.conf \
-c ident_file=${PGCONFIG}/pg_ident.conf \
-D ${PGDATA}
ExecReload=/bin/kill -HUP $MAINPID
KillMode=mixed
KillSignal=SIGINT
TimeoutSec=300
[Install]
WantedBy=multi-user.target
ExecStartPreでinitdbを行うように変更した。あと、configを読む箇所を変えたいので起動時パラメータでコンフィグのロード先を指定している。
最終的なファイル構成
こんな感じになった。
/etc/systemd/system/postgresql.service
[Unit]
Description=PostgreSQL 9.6 database server
After=syslog.target
After=network.target
[Service]
Type=notify
User=postgres
Group=postgres
PermissionsStartOnly=true
Environment=PGDATA=/var/lib/pgsql/9.6/data/
Environment=PGCONFIG=/etc/pgsql/
OOMScoreAdjust=-1000
ExecStartPre=-/usr/pgsql-9.6/bin/postgresql96-setup initdb
ExecStartPre=/usr/pgsql-9.6/bin/postgresql96-check-db-dir ${PGDATA}
ExecStart=/usr/pgsql-9.6/bin/postmaster \
-c config_file=${PGCONFIG}/postgresql.conf \
-c hba_file=${PGCONFIG}/pg_hba.conf \
-c ident_file=${PGCONFIG}/pg_ident.conf \
-D ${PGDATA}
ExecReload=/bin/kill -HUP $MAINPID
KillMode=mixed
KillSignal=SIGINT
TimeoutSec=300
[Install]
WantedBy=multi-user.target
/etc/pgsql/postgresql.conf
listen_addresses = '*' include_dir = 'conf.d'
/etc/pgsql/conf.d/replication.conf
wal_level = replica max_wal_senders = 5 max_replication_slots = 2 track_commit_timestamp = on
/etc/pgsql/conf.d/master.conf
synchronous_standby_names = '1 (pg2, pg3)'
/etc/pgsql/conf.d/slave.conf
hot_standby = on
/etc/pgsql/conf.d/logging.conf
log_destination = 'stderr' logging_collector = on log_directory = '/var/log/pg_log' log_filename = 'postgresql-%a.log' log_truncate_on_rotation = on log_rotation_age = 1d log_line_prefix = '< %m > ' log_timezone = 'UTC'
/etc/pgsql/conf.d/client.conf
datestyle = 'iso, mdy' timezone = 'UTC' lc_messages = 'en_US.UTF-8' lc_monetary = 'en_US.UTF-8' lc_numeric = 'en_US.UTF-8' lc_time = 'en_US.UTF-8' default_text_search_config = 'pg_catalog.english'
/etc/pgsql/conf.d/pgtune.conf
max_connections = 1024 shared_buffers = 1GB effective_cache_size = 3GB work_mem = 1MB maintenance_work_mem = 256MB min_wal_size = 1GB max_wal_size = 2GB checkpoint_completion_target = 0.7 wal_buffers = 16MB default_statistics_target = 100
/etc/pgsql/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD local all all peer host sameuser hoge 192.168.0.0/16 md5 host replication postgres 192.168.0.0/16 trust
/etc/pgsql/pg_ident.conf
使わないので空ファイル
再起動
ファイル巻き終わったらsystemdを更新して既存のデータディレクトリも消して再起動を行う。
systemctl daemon-reload rm -rf /var/lib/pgsql/9.6/data/* systemctl restart postgresql
この状態だと起動はするけど同期レプリケーションがいないので書き込みができない。 なのでスレイブを作成してきどうさせる必要がある。
レプリケーションスレイブの作成
同じ設定をアクティブと同様に巻く。 撒いた後はbg_backupコマンドを使ってSlave用のデータディレクトリを構成する。
su -c "pg_basebackup -R -D /var/lib/pgsql/9.6/data/ -h 192.168.0.1 -p 5432 -U postgres" postgres
バックアップを取った後、recovery.confを編集する必要がある。 色々調べたけど、このファイルはDataディレクトリにないといけないみたいだ。。。皆デプロイどうしてんだろう?
standby_mode = 'on' primary_conninfo = 'user=postgres host=192.168.0.1 port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres application_name=pg2'
application_name=pg2を追加する必要がある。
設定が終わったら起動させる。
systemctl start postgresql.service
アクティブのレプリケーション状態の確認
su -c 'psql -c "SELECT * FROM pg_stat_replication" -x' postgres -[ RECORD 1 ]----+------------------------------ pid | 30960 usesysid | 10 usename | postgres application_name | pg2 client_addr | 192.168.0.2 client_hostname | client_port | 51696 backend_start | 2017-10-05 04:58:13.243582+00 backend_xmin | state | streaming sent_location | 0/7000060 write_location | 0/7000060 flush_location | 0/7000060 replay_location | 0/7000060 sync_priority | 1 sync_state | sync
同期レプリされてるっぽいぞ。 おkおk。
終わりに
postgresqlの設定をイジってレプリが組めるところまで実施した。 本番デプロイに向けて、後はフェイルオーバーをコントロールするサーバと同期レプリカの候補サーバがもう一台あったほうが良いだろう。
kyoto tycoonのDocker Imageを作る
あらすじ
私の所属する会社は未だバリバリにkyoto tycoon(kt)というkvsを使っている。 このktをいっちょDocker化したるか!と思ったら色々ハマったので備忘兼ねて記録を残す。
すでにDockernizeしてる人がいた
ネットを漁ると、すでにDocker化している方がいた。
先人の知恵に感謝しつつも、上記のDockerfileを覗くと、alpineのバージョンが3.4で固定されいる。
怪訝に思いながらも、それ以外に、会社で使用するkyototycoonはluaスクリプトによる拡張を有効化する必要があっため、大部分を参考にしつつ自前でDockerfile書くことにした。
ついでにalpineも最新の3.5で作ることにした。
自前で書く、といってもluaのパッケージを追加して、make前のconfigureで--enable-luaオプションを付加するだけだろうと思っていた。
alpine3.5でビルドが通らない問題
いざDockerfileを書いてbuildしようしたが、alpine3.5だと以下のようなエラーが出てmakeでこけてしまった。
g++ -c -I. -I/usr/local/include -I/usr/local/include -DNDEBUG -D_GNU_SOURCE=1 -D_FILE_OFFSET_BITS=64 -D_REENTRANT -D__EXTENSIONS__ -D_MYZLIB -D_MYGCCATOMIC -D_KC_PREFIX="\"/usr/local\"" -D_KC_INCLUDEDIR="\"/usr/local/include\"" -D_KC_LIBDIR="\"/usr/local/lib\"" -D_KC_BINDIR="\"/usr/local/bin\"" -D_KC_LIBEXECDIR="\"/usr/local/libexec\"" -D_KC_APPINC="\"-I/usr/local/include\"" -D_KC_APPLIBS="\"-L/usr/local/lib -lkyotocabinet -lz -lstdc++ -lrt -lpthread -lm -lc \"" -std=c++11 -march=native -m64 -g -O2 -Wall -fPIC -fsigned-char -g0 -O2 -Wno-unused-but-set-variable -Wno-unused-but-set-parameter kcdbext.cc
In file included from kcdbext.cc:16:0:
kcdbext.h: In member function 'char* kyotocabinet::IndexDB::get(const char*, size_t, size_t*)':
kcdbext.h:1281:14: error: cannot convert 'bool' to 'char*' in return
return false;
^~~~~
make: *** [Makefile:76: kcdbext.o] Error 1
luaの部分がおかしいのかと思いきや、alpine3.4だと上手くいく。 コンパイルでエラーが出ているので、alpine3.4と3.5のg++とgccのバージョンを確認すると、alpine3.4のほうがgccのバージョンが5系でalpine3.5のほうがgccが6系となっていた。 デフォルトのコンパイルオプションとかが変わったのかな?とか思いながら、ググっていると以下の記事にたどり着いた。
どうやらgccの6系は標準で利用するc++の規格が変わってしまったようだ。 ktは古いプログラムなので、上手くコンパイルできないのであろう。
解決策
というわけでDockerfile内でsedを使って強引にMakefileを書き換えて、c++98を使ってbuildするようにすれば、makeが通るようになった。
sed -i -e "s/CXXFLAGS =/CXXFLAGS = -std=c++98/" ./Makefile && \ sed -i -e "s/CFLAGS =/CFLAGS = -std=c++98/" ./Makefile
余談
色々なDockefileを見てるとsedで強引にファイルを書き換えているものを良く見るが、個人的にこれはイマイチな気がしている。 しかし、他にいい方法も思いつかないので、安易にsedっている。 Dockerfileでshell芸よろしくゴリゴリ書くの、みんな満足しているのだろうか?? 個人的には何かキッティングツールが欲しいと思うのだが、いまいちPackerとかがDockerのビルドに使われてる感を感じないんだなぁ。
追記
ありがたいことに会社で同僚に指摘してもらった。sedなんかせずともconfigure実行時にパラメータをつければ良いらしい。 ふむふむ後でDockerfileも変更しとこう、ついでにmulti-stage build化でもしとくかな。
./configure CFLAGS='-std=c++98' CXXFLAGS='-std=c++98' --enable-lua --with-kc=/usr/local
まとめ
今回作ったDockerImageは以下にアップした。